随机森林算法原理
Bagging模型的代表作是大名鼎鼎的随机森林(Random Forest, RF)。RF默认采用CART作为基学习器,而且它在Bagging模型的基础上再进一步,每次训练基学习器时,除了样本随机采样外,对样本的特征也进行随机采样。
如图所示:
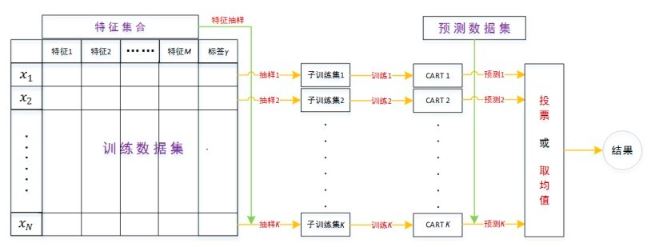
由于采用的是CART,所以RF既可以用来做分类,也可以用来回归。RF用来分类时使用CART分类树作为基学习器,最后的投票结果是取票数最多的类别作为最终的预测结果;RF用来回归时使用CART回归树作为基学习器,最后的预测结果采用所有CART回归树的预测值的均值。
由于RF每次都是对样本及样本的特征进行随机采样来训练基学习器,因此泛化能力较强。
总结:
树模型本身具有较强的非线性拟合能力,在分类和回归问题中都表现得比较出色,而RF是将多棵CART树进行集成,使其功能更加强大,RF每次都是通过随机抽取训练样本中的一部分样本和随机选择被抽取样本的一部分特征进行单个基模型的训练,一方面增强了模型的泛化能力,另一方面各个模型的训练过程都是相互独立的,可以并行进行。
优点:
(1)RF各个基学习器之间没有强关联,因此学习过程可以分开,实现并行化。
(2)由于RF每次训练时,各个基学习器只是抽取样本的部分特征进行训练,因此对于样本特征维度很高的情况,RF仍能高校地训练模型。
(3)由于RF的每个基学习器只是随机抽取部分样本和部分特征进行学习,因此模型的泛化能力较强。
(4)由于RF采用的基学习器是CART决策树,而CART决策树对缺失值不敏感,因此RF对部分特征确实也不敏感。
(5)RF训练模型后可以顺便输出各个特征对预测结果的重要性,因此可以辅助进行特征选择。
缺点:
RF的基学习器采用了决策树模型,而决策树模型的一个缺点似乎对噪声比较敏感,所以RF在某些噪声较大的样本集上容易产生过拟合。